Abstract
Concepts such as objects, patterns, and shapes are how humans understand the world.
Building on this intuition, concept-based explainability methods aim to study representations learned by deep neural networks in relation to human-understandable concepts.
Here, Concept Activation Vectors (CAVs) are an important tool and can identify whether a model learned a concept or not.
However, the computational cost and time requirements of existing CAV computation pose a significant challenge, particularly in large-scale, high-dimensional architectures.
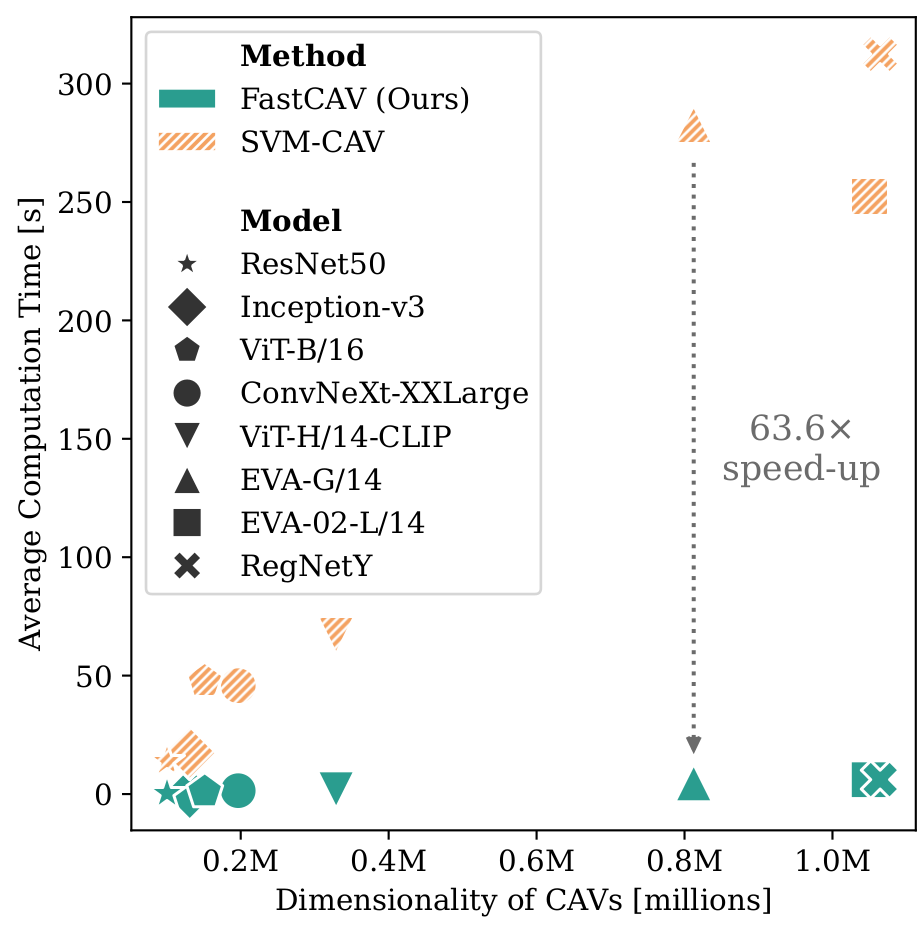
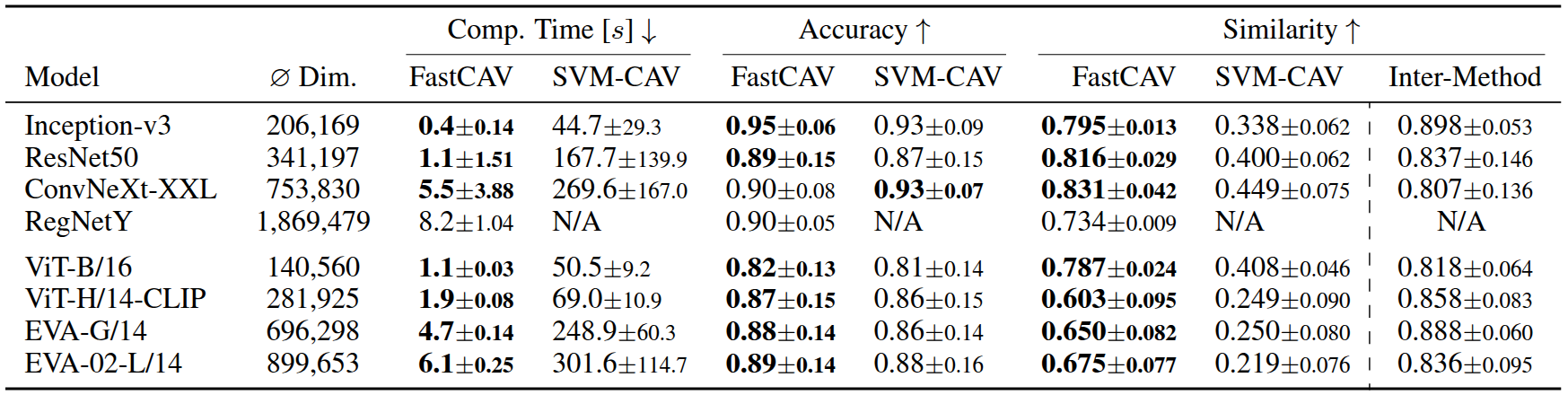
To address this limitation, we introduce FastCAV, a novel approach that accelerates the extraction of CAVs by up to 63.6× (on average 46.4×).
We provide a theoretical foundation for our approach and give concrete assumptions under which it is equivalent to established SVM-based methods.
Our empirical results demonstrate that CAVs calculated with FastCAV maintain similar performance while being more efficient and stable.
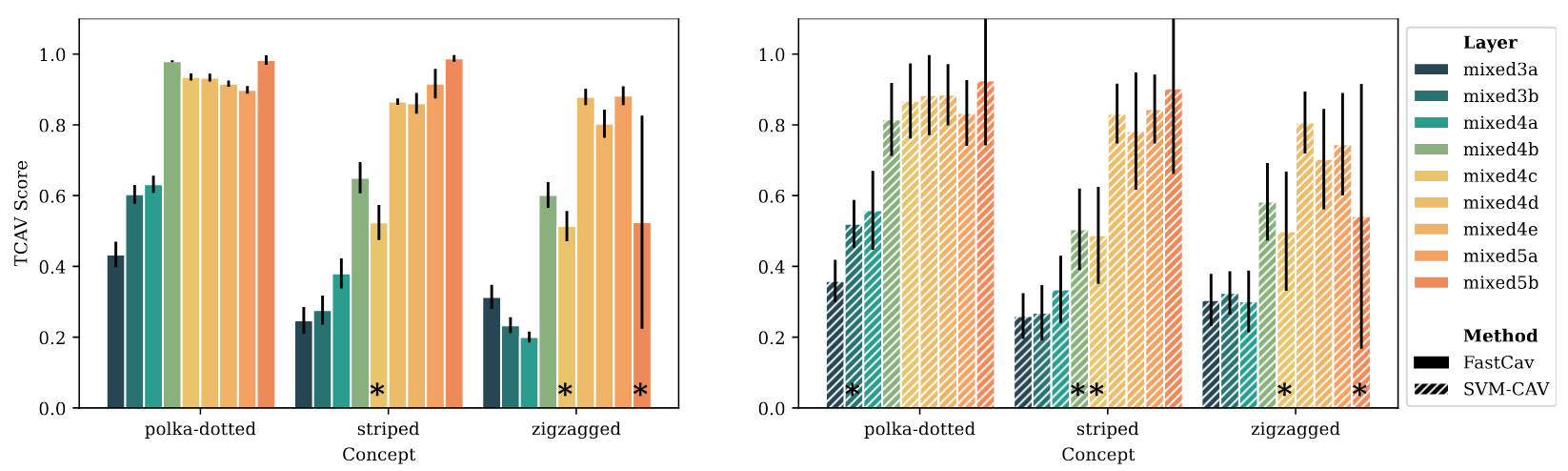
In downstream applications, i.e., concept-based explanation methods, we show that FastCAV can act as a replacement leading to equivalent insights.
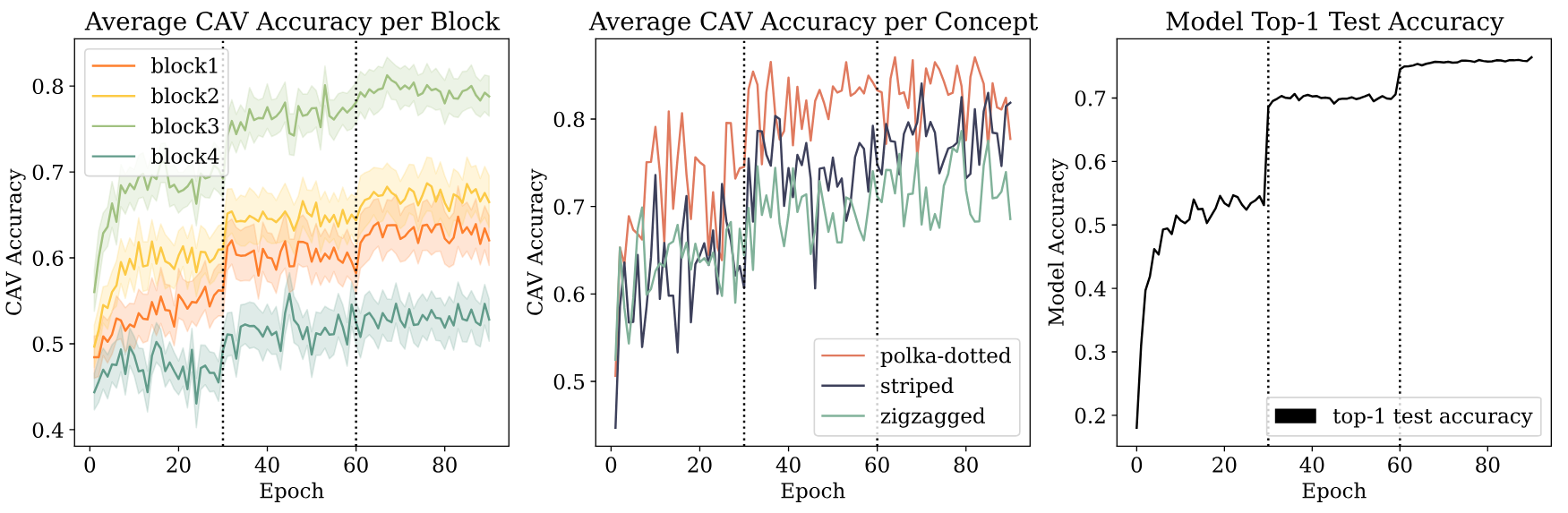
Hence, our approach enables previously infeasible investigations of deep models, which we demonstrate by tracking the evolution of concepts during model training.